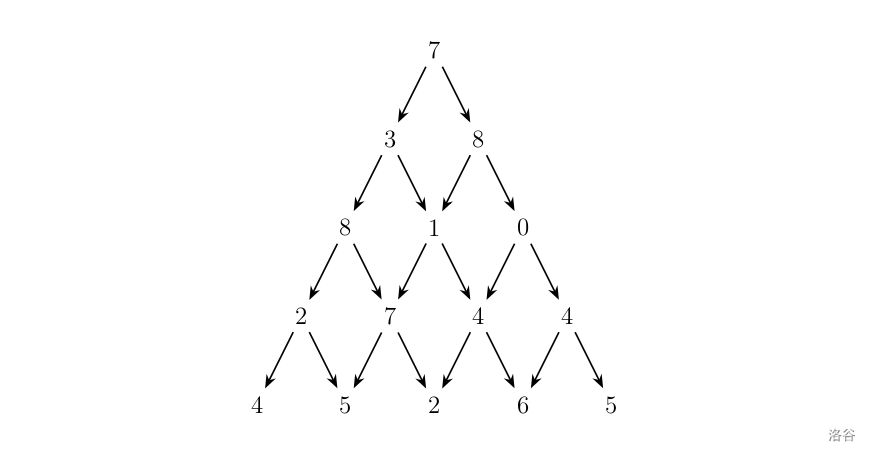
组合数
众所周知,组合数有两种求法。
- 杨辉三角求法:$\dbinom{i}{j}=\dbinom{i-1}{j}+\dbinom{i-1}{j-1}$
- 定义法:$\dbinom{i}{j}=\Large\frac{n!}{m!(n-m)!}$
其中,杨辉三角的空间占用很大,所以除非数据量较小(如:$N\leqslant 10^{4}$)的情况,我们不会使用这种求法,但是这种求法可以实现 $O(1)$ 查询,因此它也适用于需要大量查询的题目。而定义法适用于不需要大量查询(至少没有杨辉三角的情况多)的题目,但是因为有阶乘的存在,使得实现 $O(1)$ 还需要一点点数学上的优化,并且,其适用的数据范围($N\leqslant 10^5$)一般都需要 $\text{mod}$ 一个极大数(阶乘不 $\text{mod}$ 留着爆 $\text{long long}$ 吗),然而我们都知道,同余的性质不适用于除法,这导致我们处于一个进退两难的地步。
古语有云:$\text{To modulo or not to do, it’s a question.}$
这时候,我们就需要乘法逆元来帮忙了。
乘法逆元
按照惯例,先说定义:如果一个线性同余方程 $ax\equiv 1(\mathrm{mod}\;b)$ ,则称 $x$ 为 $a\;\mathrm{mod}\;b$ 的逆元,记为 $a^{-1}$ 。我们可以把它理解成倒数,一种在模 $p$ 意义下的倒数。因此,我们可以知道一个数逆元的逆元就是这个数本身。
逆元的求法有两种:
Extend-GCD 拓展欧几里得法
就是直接解上述定义中的方程,没什么好说的。
1 | void exgcd(int a, int b, int &x, int &y) { |
快速幂法
$\huge 使用这玩意的前提是\;b\;为质数!$
证明:
$\because ax\equiv 1(\mathrm{mod}\;b)$
由费马小定理: $a^{p-1}\equiv1(\mathrm{mod}\;b)$
得 $ax\equiv a^{p-1}(\mathrm{mod}\;b)$
$\therefore x\equiv a^{p-2}(\mathrm{mod}\;b)$
所以我们可以直接写一个快速幂板板!
1 | int power(int a, int b) { |
除此之外,我们还可以使用线性递推求一大串数的逆元(但是我不会推)。
$i^{-1}\equiv\begin{cases}1&\mathrm{if}\;i=1\-\left\lfloor\dfrac{p}{i}\right\rfloor (p\;\mathrm{mod}\;i)^{-1}&\mathrm{otherwise.}\end{cases}\;(\mathrm{mod}\;p)$
那么,归根结底,我们到底如何使用乘法逆元加速定义法的组合数呢?
乘法逆元优化组合数
我们不能使用定义法求带模组合数是因为除法不具备同余的性质,但是,我们可以用逆元将除法转化为乘法,进而求出组合数。
那么,原来的定义法公式可以转化为 $\dbinom{i}{j}=\large n!\times inv[m] \times inv[n-m]$(还是说可以把逆元理解为倒数)
首先,$n!$ 是可以预处理出来的,而 $inv[i]$ 使用上面说的两种方式很明显会 $TLE$ (但事实上并不会) ,剩下的只有一条路了——递推。
首先,我们还是可以使用上面说到的递推公式,但是对于阶乘,我们还有另一个递推公式:
$$inv[i!]=inv[(i+1)!]\times (i+1)$$
怎么理解呢?还记得我们说过,逆元就是一种倒数吗?借此,有如下公式:
$$ \frac{1}{i!}=\frac{1}{(i+1)!}\times (i+1) $$
答案已经呼之欲出了!